
RAPPRESENTAZIONI ANALITICHE
INDICI
Riferimento al libro “Statistica: principi e metodi”: capitolo 5 “Indici di variabilità”
variabilità = attitudine di un fenomeno naturale o sociale ad assumere diverse modalità
indici di variabilità = misurano il fenomeno della variabilità, sono nulli in assenza di variabilità (cioè quando tutti i termini della distribuzione sono uguali tra di loro) e possono essere suddivisi in tre categorie
• indici di dispersione = scostamenti medi = sono basati sulle differenze tra i singoli termini di una distribuzione e valori caratteristici come la media aritmetica o la mediana
• indici di disuguaglianza o differenze medie = sono basati sulle differenze tra tutti i termini della distribuzione presi due a due
• indici basati sugli intervalli di variazione = sono basati sulle differenze tra medie di posizione o tra termini che occupano specifiche posizioni nella graduatoria dei valori ordinati della distribuzione
Gli indici di variabilità si inseriscono nella più ampia classificazione degli indici statistici
indici assoluti di variabilità = sono espressi nella stessa unità di misura propria del carattere e non sono idonei per il confronto di variabilità di più distribuzioni
indici percentuali di variabilità = si ricavano moltiplicando per 100 il rapporto tra gli indici assoluti e la media aritmetica
schema minimante di variabilità = tutti i termini della distribuzione sono uguali fra loro, cioè la popolazione è omogenea rispetto a un carattere (che risulta concentrato in una sola modalità di frequenza assoluta N)
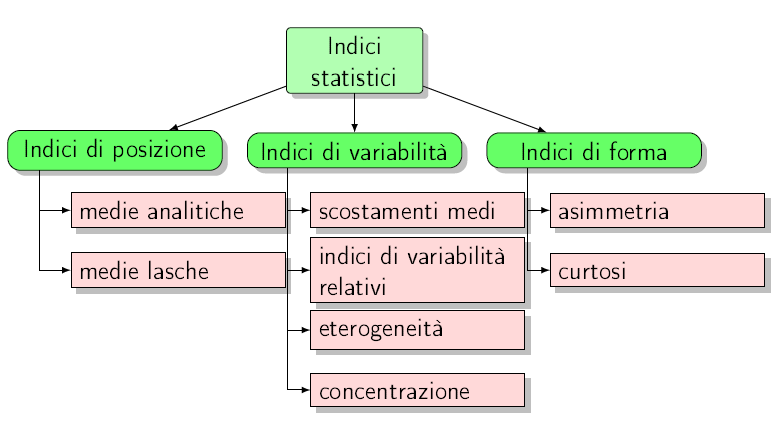
schema massimante di variabilità = distribuzione con due sole modalità, una maggiore dell’altra, con frequenze assolute rispettivamente pari a p e q, la cui somma corrisponde al totale N delle frequenze osservate nella distribuzione di partenza o, alternativamente, distribuzione in cui una sola unità possiede tutto il fenomeno e le altre n-1 unità hanno la modalità pari a zero
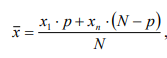

Fonti di variabilità = fattori che possono essere intrinsechi dell’oggetto che si sta misurando, oppure riguardare
elementi che entrano in gioco nello svolgimento dell’indagine o dell’esperimento
MISURA DELLA VARIABILITÀ
INDICI DI VARIABILITÀ
• scostamento semplice medio = indice di variabilità dato dalla media aritmetica degli scarti dalla media aritmetica presi in valore assoluto
CALCOLO DELLO SCOSTAMENTO SEMPLICE MEDIO PER UNA DISTRIBUZIONE DISAGGREGATA:
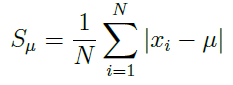
CALCOLO DELLO SCOSTAMENTO SEMPLICE MEDIO PER UNA DISTRIBUZIONE DI FREQUENZE
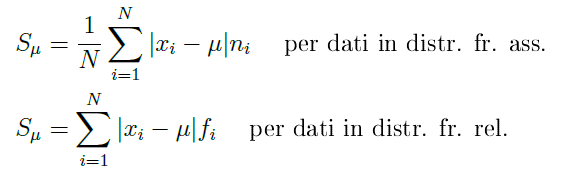
CALCOLO DELLO SCOSTAMENTO SEMPLICE MEDIO PER UNA DISTRIBUZIONE DI FREQUENZE PER CLASSI
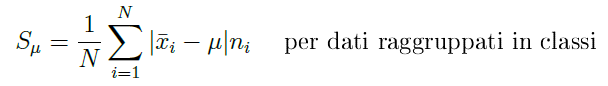
• devianza = somma dei quadrati degli scarti dalla media = varianza moltiplicata per N
• varianza = media aritmetica dei quadrati degli scarti dei valori dalla loro media
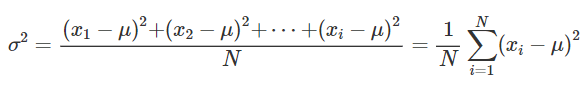
Le formule per il calcolo della varianza per distribuzioni di frequenze o per dati raggruppati in classi sono analoghe a quelle per la deviazione standard, ma senza radice quadrata
• scarto/scostamento quadratico medio = deviazione standard = indice di variabilità dato dalla media quadratica degli scarti/radice quadrata della varianza
CALCOLO DELLO SCARTO QUADRATICO MEDIO PER UNA DISTRIBUZIONE DISAGGREGATA
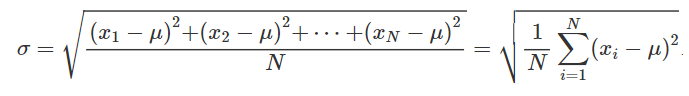
Formula alternativa:
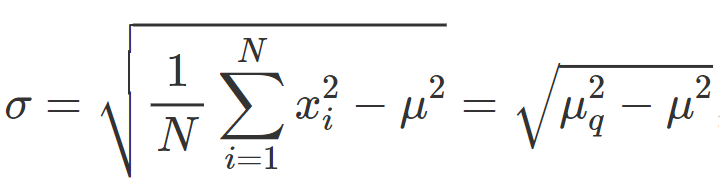
CALCOLO DELLO SCARTO QUADRATICO MEDIO PER UNA DISTRIBUZIONE DI FREQUENZE
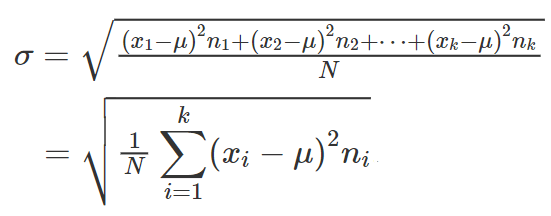
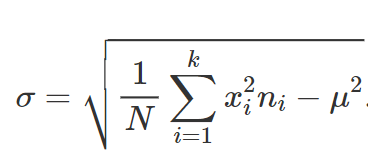
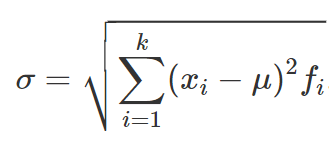
CALCOLO DELLO SCARTO QUADRATICO MEDIO PER UNA DISTRIBUZIONE DI FREQUENZE PER CLASSI
valore centrale di una classe = x̄i = media tra gli estremi di una classe = (ci+ci-1)/2
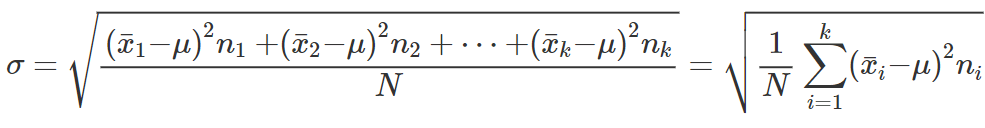
Formula operativa
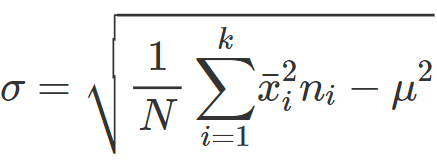
Proprietà dello scostamento semplice medio, dello scarto quadratico medio e della varianza

Indici di variabilità relativi e percentuali
• differenza semplice media = la media aritmetica tra le N*(N-1) coppie di termini della distribuzione
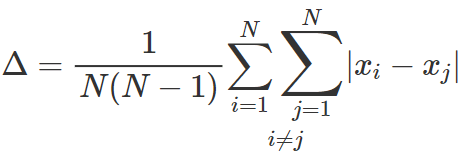
PROPRIETÀ DELLA DIFFERENZA SEMPLICE MEDIA
La differenza semplice media presenta le stesse proprietà della deviazione standard.
FORMULA OPERATIVA DELLA DIFFERENZA SEMPLICE MEDIA
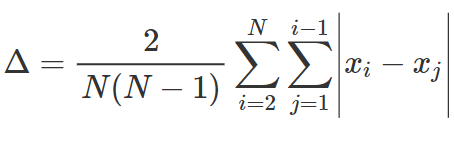
• coefficiente di variazione = è un indice percentuale che si ottiene moltiplicando per 100 il rapporto tra deviazione standard e media aritmetica e pertanto permette di eliminare l’influenza che il livello medio del carattere ha sulla misura della variabilità
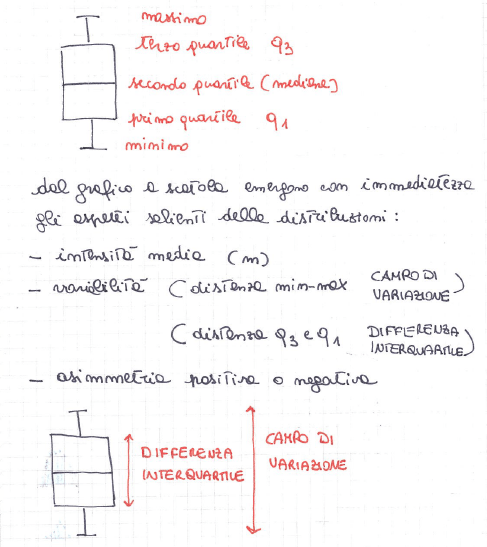
• campo di variazione = la differenza tra il valore più grande e quello più piccolo della distribuzione
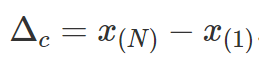
• differenza interquartile = la differenza tra il terzo e il primo quartile della distribuzione
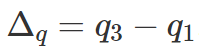
concentrazione = concetto che si usa con i caratteri quantitativi per indicare come è ripartito il carattere tra le varie unità

SCHEMA DI MINIMA CONCENTRAZIONE (EQUIDISTRIBUZIONE) E SCHEMA DI MASSIMA CONCENTRAZIONE

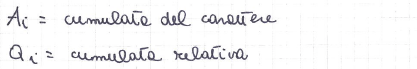
MISURA DELLA CONCENTRAZIONE PER LE DISTRIBUZIONI DISAGGREGATE
Indice di concentrazione di Gini per distribuzioni disaggregate: assoluto e relativo (rapporto di concentrazione)



Proprietà dell’indice di concentrazione Gini
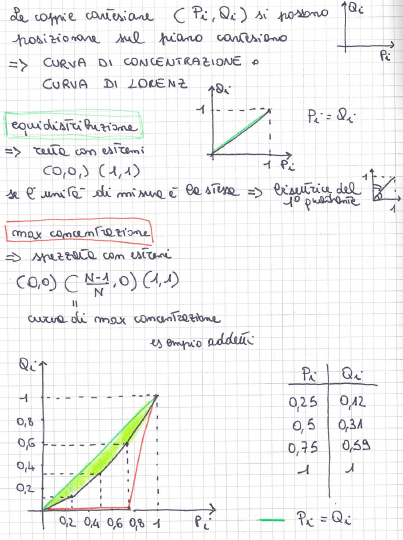
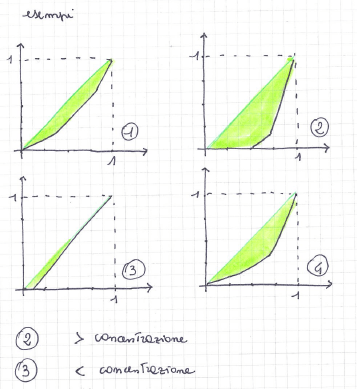
Curva di concentrazione o di Lorenz = spezzata che si ottiene congiungendo con segmenti di retta le coppie consecutive di punti di coordinate (0,0), (P1, Q1), (Pi, Qi), … , (PN,QN), (1,1);
Area di concentrazione = l’area compresa tra la spezzata di concentrazione e il segmento di retta con estremi (0,0) e (1,1). È tanto maggiore quanto maggiore è la concentrazione.
Curva di (massima) concentrazione = spezzata che unisce i punti (0,0), ((N-1)/N, 0), (1,1)
Segmento di equidistribuzione = segmento avente come estremi i punti (0,0) e (1,1)
Eterogeneità: si usa per i caratteri qualitativi (non trasferibili), per cui non si può parlare di variabilità, al posto della concentrazione. Non potendo lavorare con le modalità, si lavora con le frequenze. Attenzione, si usa un altro indice di Gini per l’eterogeneità, diverso da quello visto per la concentrazione
Schema minimante e massimante di eterogeneità.
Alla massima concentrazione corrisponde la minima eterogeneità (omogeneità massima, tutte le unità del collettivo hanno la stessa modalità del carattere)

Alla minima concentrazione corrisponde la massima eterogeneità (omogeneità minima, tutte le unità del collettivo hanno la stessa frequenza

• Indice di eterogeneità di Gini = si calcola così (con fi = frequenze relative):
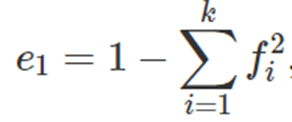
massimo dell’indice di eterogeneità di Gini = (k-1)/k e si tocca nel caso di massima eterogeneità (mentre nel caso di minima eterogeneità l’indice di eterogeneità di Gini è 0)
• Indice di entropia di Shannon = si calcola così (con fi = frequenze relative e ln (fi) = logaritmi naturali, cioè con base e=numero di Nepero, delle frequenze relative):
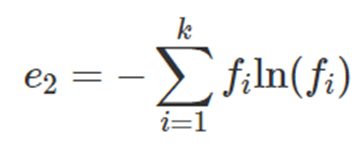
massimo dell’indice di entropia di Shannon = ln (k) e si tocca nel caso di massima eterogeneità (mentre nel caso di minima eterogeneità l’indice di entropia di Shannon è 0)
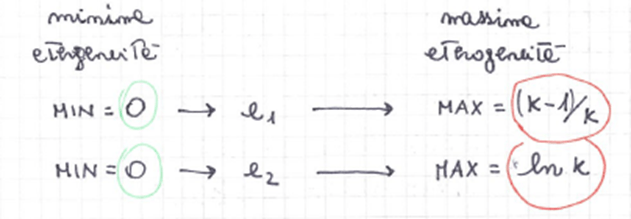
Gli indici vanno sempre raffrontati al valore minimo e massimo che possono avere.
Indice di eterogeneità di Gini relativo al massimo
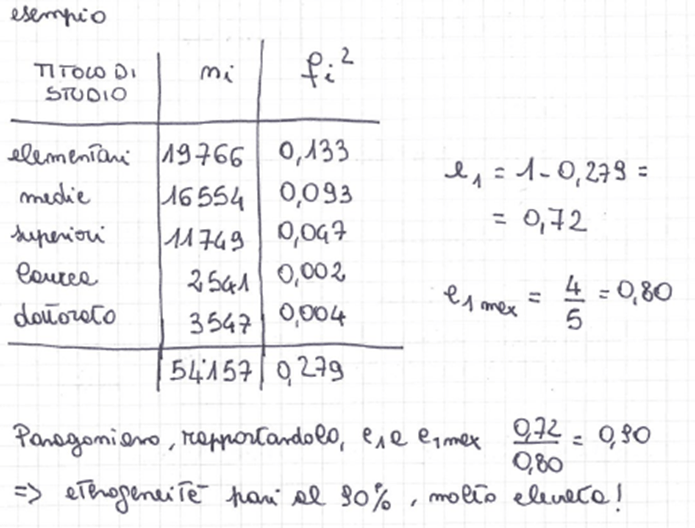
indice di entropia di Shannon relativo al massimo


INDICI DI FORMA
Riferimento al libro “Statistica: principi e metodi”: capitolo 6 “Indici di forma”
Indici di forma = indicatori sintetici delle caratteristiche delle distribuzioni statistiche
PROPRIETÀ DI UNA DISTRIBUZIONE SIMMETRICA
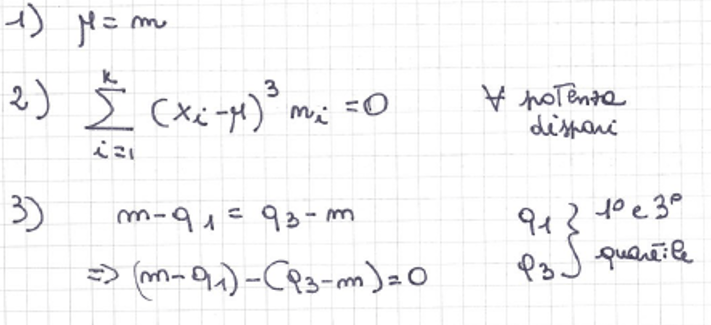
ASIMMETRIA: può essere POSITIVA E NEGATIVA a seconda del segno del primo indice (media maggiore della mediana o viceversa)
Indice analitico di asimmetria e indice di asimmetria basato sui quartili =
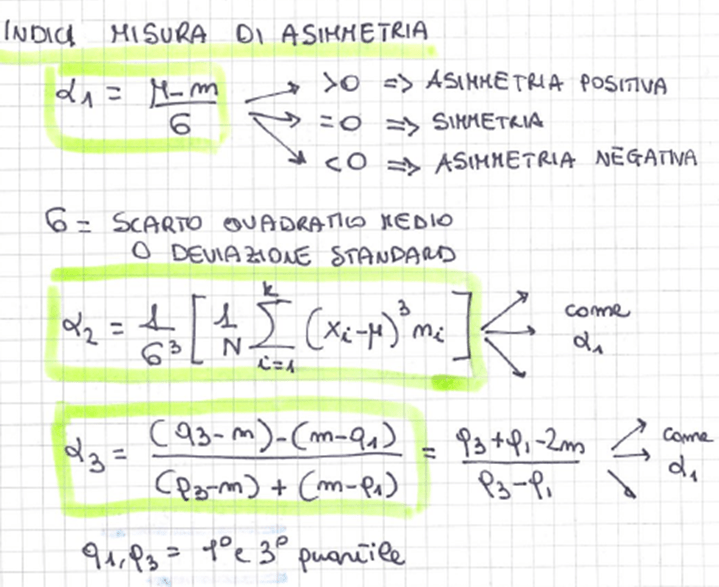
ESEMPI DI CURVE SIMMETRICHE E ASIMMETRICHE
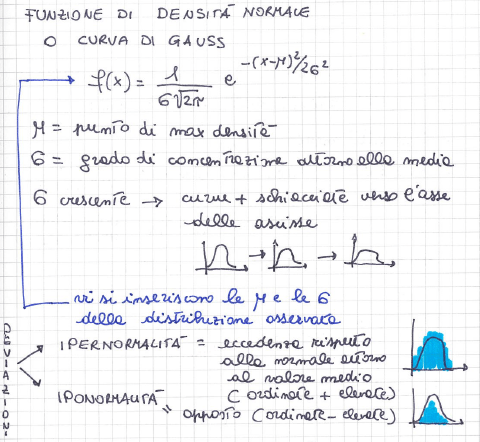
Diagramma a scatola
NUMERI INDICI
Riferimento al libro “Statistica: principi e metodi”: capitolo 8 “Numeri indici”
• numeri indici a base fissa

ESEMPI DI CALCOLO DI NUMERI INDICI A BASE FISSA
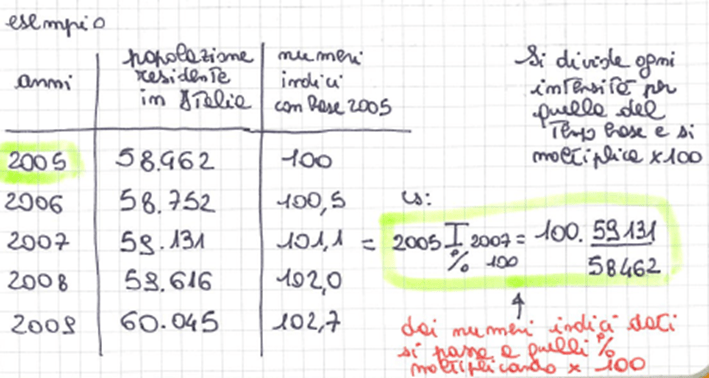
• numeri indici a base mobile
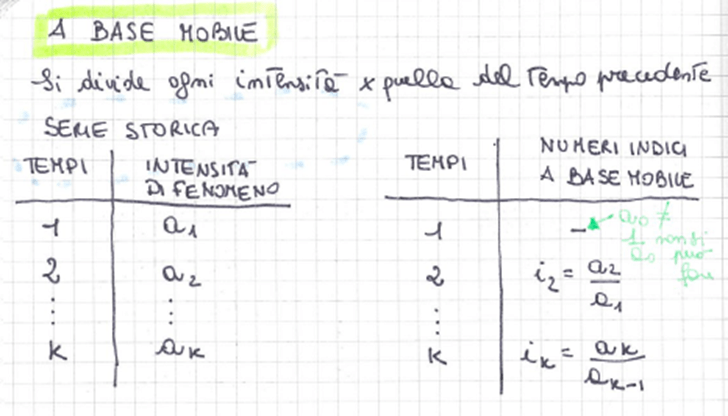
ESEMPI DI CALCOLO DI NUMERI INDICI A BASE MOBILE

Variazioni relative e percentuali.
Le variazioni percentuali si ottengono moltiplicando quelle relative per 100

• numeri indici semplici e complessi e problematiche nel calcolo dell’inflazione

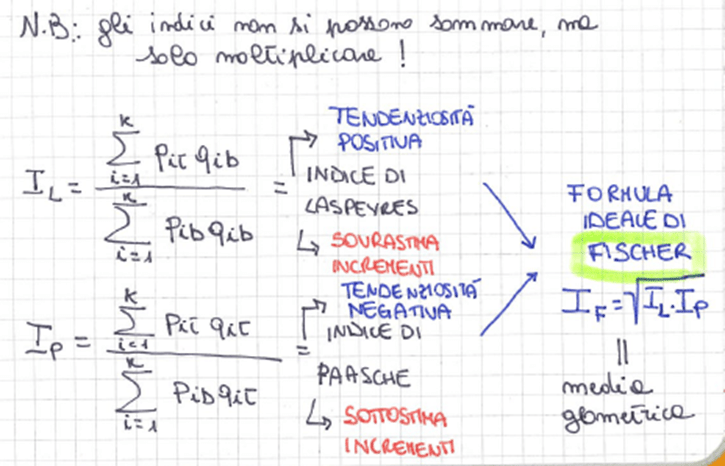
• numero indice di Laspeyres = media aritmetica ponderata utilizzando le quantità al tempo base. Ha tendenziosità positiva in caso di inflazione, ma è la formula più applicata
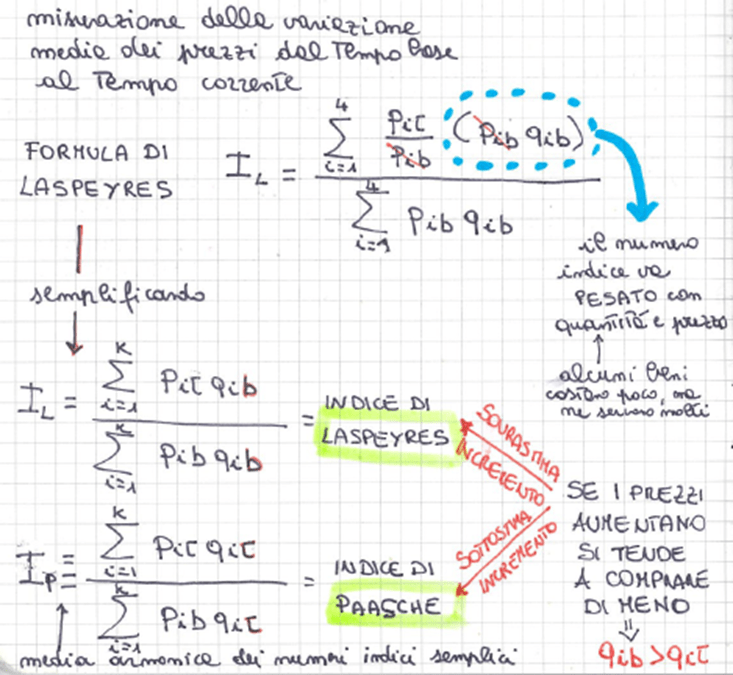
• numero indice di Paasche = media aritmetica ponderata utilizzando le quantità al tempo corrente. Ha tendenziosità negativa in caso di inflazione
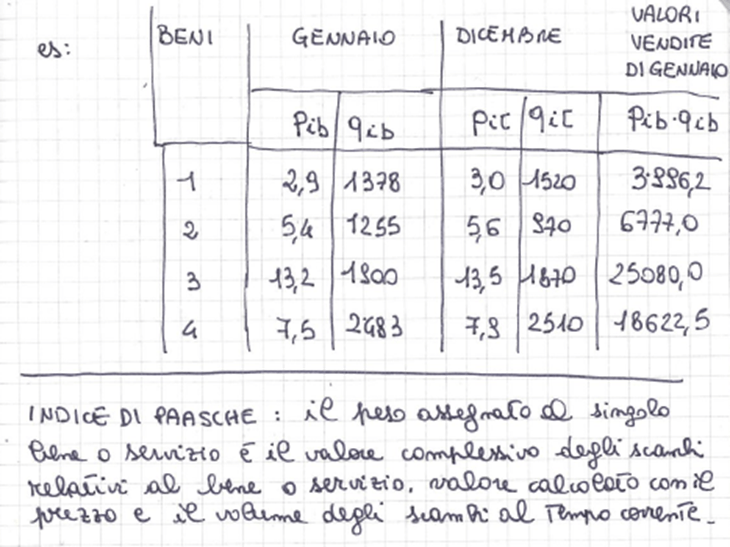
• numero indice di Fisher = media geometrica tra il numero indice di Laspeyres e il numero indice di Paasche (formula ideale, in quanto riassorbe le tendenziosità degli altri due)
DIPENDENZA E INTERDIPENDENZA TRA CARATTERI
RELAZIONI TRA CARATTERI QUANTITATIVI
distribuzione doppia = si esaminano congiuntamente due caratteri nelle unità statistiche del collettivo
distribuzione doppia disaggregata = elencazione delle modalità di due caratteri (X e Y) osservate per ogni unità statistica del collettivo considerato: (x1,y1), (x2,y2), …,(xN,yN).
distribuzione doppia di frequenze = sintesi della distribuzione doppia disaggregata di due caratteri, che viene rappresentata tramite una tabella a doppia entrata o di contingenza
tabella a doppia entrata = tabella di contingenza = presenta nell’intestazione delle righe le diverse modalità del carattere X e nell’intestazione delle colonne le diverse modalità del carattere Y e per ogni coppia di modalità dei due caratteri viene indicata la corrispondente frequenza congiunta (nij ) per ogni coppia di modalità di due caratteri (xi,yj), con i che varia da 1 a h e j che varia da 1 a h.
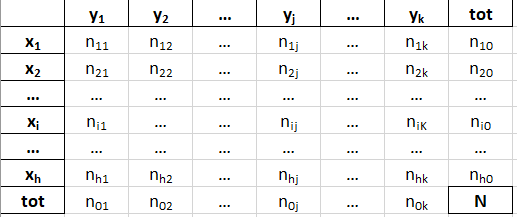
frequenza congiunta = nij = numero delle unità del sottoinsieme xi∩yj, cioè in cui si verificano contemporaneamente le modalità xi e le modalità yj. La doppia sommatoria di tutte le frequenze congiunte al variare di i da 1 a h e di j da 1 a k restituisce N come risultato.
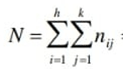
Distribuzione marginale = distribuzione statistica semplice delle N unità statistiche secondo uno dei caratteri.
Ad esempio:
distribuzione marginale delle N unità statistiche secondo il carattere X è data da tutte le ni0, al variare di i da 1 ad h (n10, n20,…,ni0,…,nh0), in cui ognuna delle ni0 è data dalla somma di tutte le nij ottenuta tenendo fissa la i e facendo variare la j da 1 a k.
distribuzione marginale delle N unità statistiche secondo il carattere Y è data da tutte le n0j, al variare di j da 1 ad k (n01, n02,…,n0j,…,n0k), in cui ognuna delle n0j è data dalla somma di tutte le nij ottenuta tenendo fissa la j e facendo variare la i da 1 a h.
La somma di tutte frequenze congiunte (o di tutte le frequenze marginali) corrisponde alla numerosità del collettivo:

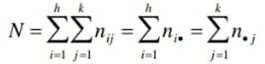

distribuzione condizionata di un carattere data una modalità dell’altro carattere
Ad esempio:
- la distribuzione condizionata del carattere Y dato X=xi è la distribuzione di Y limitatamente ai soggetti che presentato la modalità xi di X. Si ottiene associando a ogni modalità yj di Y la frequenza congiunta di (xi,yj), tenendo fissa xi.
Ogni riga della tabella a doppia entrata corrisponde a una distribuzione condizionata di Y per una certa modalità di X.
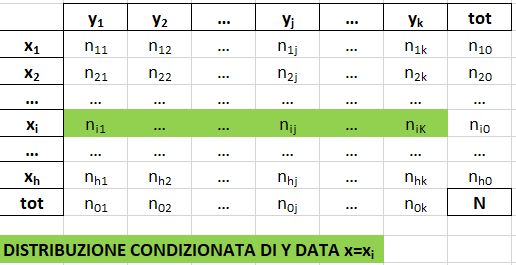
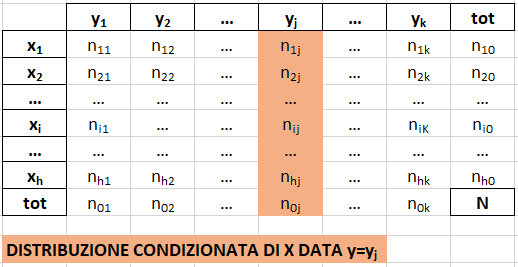
- la distribuzione condizionata del carattere X dato Y=yj è la distribuzione di Y limitatamente ai soggetti che presentato la modalità yj di X. Si ottiene associando a ogni modalità xi di X la frequenza congiunta di (xi,yj), tenendo fissa yj .
Ogni colonna della tabella a doppia entrata corrisponde a una distribuzione condizionata di X per una certa modalità di Y.
dipendenza = al variare delle determinazioni assunte da una variabile si modifica una qualche
caratteristica della distribuzione dell’altra
Ad esempio da questa tabella si evince una certa dipendenza di un carattere dall’altro, in quanto maggiore è il numero di componenti di una famiglia, maggiore è il numero di vani della loro casa:

indipendenza = la conoscenza della determinazione di una variabile non fornisce alcuna informazione sulla probabile determinazione dell’altra
tabella di indipendenza = si ottiene inserendo in ogni cella la
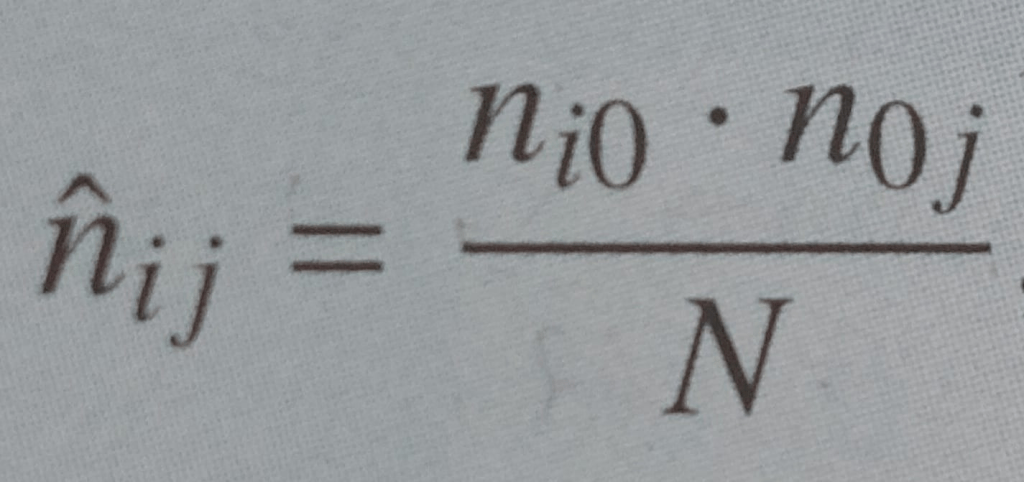
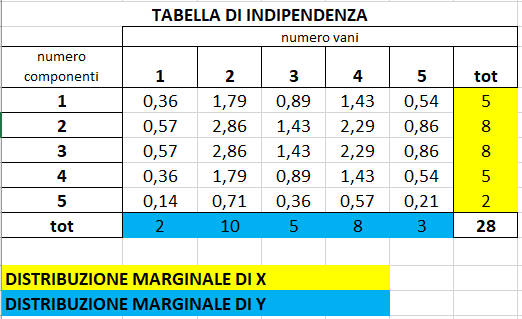
Ad esempio la cella n34 di seguito si ottiene moltiplicando la frequenza marginale n30 moltiplicata per la frequenza marginale della quarta colonna n04

tabella di contingenza = tabella in cui si inseriscono le contingenze, che sono alla base di un indice di dipendenza ψ
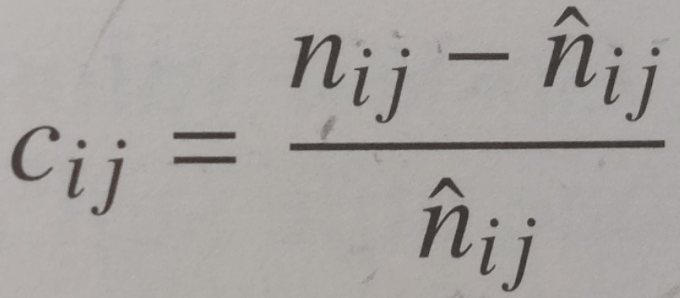


interdipendenza = dipendenza bilaterale in cui le variabili hanno lo stesso ruolo nell’analisi
tabella di dipendenza perfetta = a ogni modalità del carattere X corrisponde una sola modalità del carattere Y (in ogni riga della tabella le frequenza sono tutte nulle, tranne una che è il totale di riga o in ogni colonna della tabella le frequenze sono tutte nulle, tranne una che è il totale di colonna)
REGRESSIONE (si calcola se è ipotizzabile un rapporto di “causa-effetto” tra le variabili)
Modello di regressione (di Y su X) = modello matematico che cerca di determinare la relazione tra una variabile dipendente (Y), rispetto a una variabile indipendente (X). La relazione statistica si indica con la funzione matematica f(x) a cui viene sommata la componente residuale
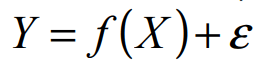
Funzione matematica = componente deterministica = f(x) = funzione che dà il contributo della variabile indipendente X al livello della variabile risposta Y a livello teorico
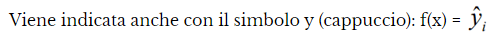
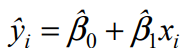
Componente residuale =componente stocastica = ε = contributo di tutti i fattori che potrebbero influire sulla variabile risposta e che non vengono considerati, il cui valore è dato dalla differenza tra i valori effettivi e quelli teorici di yi
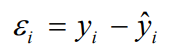
Modello di regressione lineare = modello matematico che cerca di determinare la relazione tra una variabile dipendente (y), rispetto a una variabile indipendente (x) mediante una funzione lineare (si chiama regressione grazie all’esperimento che coinvolgeva le altezze di padri e figli in cui Galton notò che le altezze dei figli con i padri più alti o più bassi tendevano ad avvicinarsi alla media)
Funzione lineare = funzione che esprime la relazione tra la variabile y e la variabile x mediante un’equazione lineare
Equazione lineare = equazione esprimibile mediante un polinomio di grado 0 (ad esempio y=β0, che è equivalente a y=β0x0, in quanto ogni quantità elevata alla 0 equivale a 1) o di grado 1 (ad esempio y=β0x+β0, che è equivalente a y=β1x1+β0x0, in quanto ogni quantità elevata alla 0 equivale a 1 e ogni quantità elevata alla 1 equivale a se stessa)
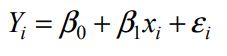
Grado di un polinomio = esponente massimo a cui compare elevata la x
Metodo dei minimi quadrati (in inglese OLS: Ordinary Least Squares) = una tecnica di ottimizzazione che ha lo scopo di trovare una funzione, rappresentata da una curva di regressione, che si accosti il più possibile ad un insieme di dati, in genere rappresentati da punti del piano
Stima dei parametri del modello lineare =viene effettuata in modo che si minimizzi la somma degli scarti quadratici
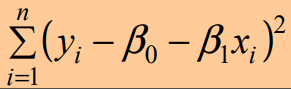
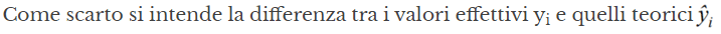
retta di regressione di Y su X = retta interpolatrice dei minimi quadrati = retta che si ottiene una volta calcolati i valori dei parametri b0 e b1 che minimizzano gli scarti
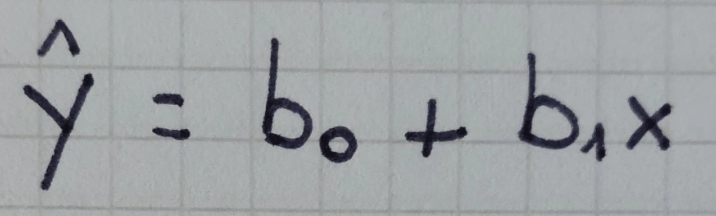
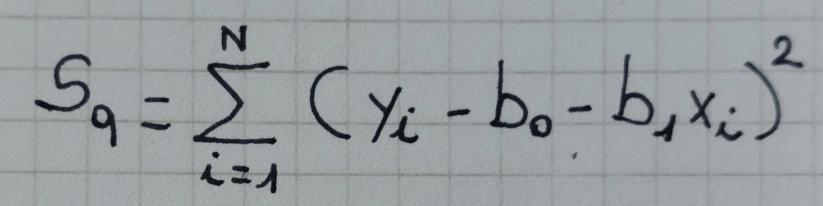
I parametri così stimati sono i seguenti:
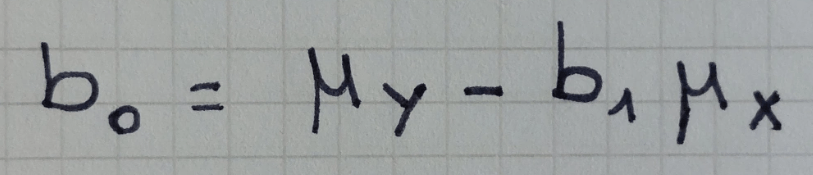

ESEMPIO DI CALCOLO DEI PARAMETRI
INTERPRETAZIONE DEI PARAMETRI DELLA RETTA DI REGRESSIONE
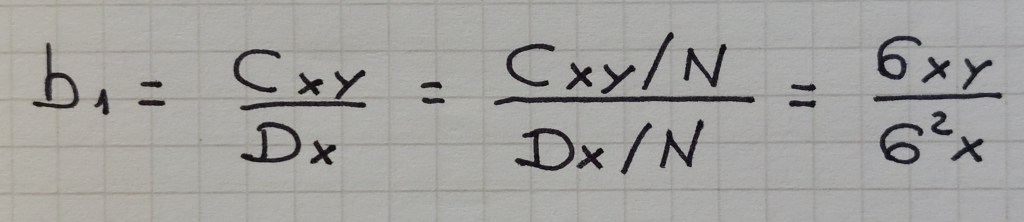
L’ultimo termine a destra si ottiene dividendo sia la codevianza che la devianza per N.
codevianza = Cxy = somma dei prodotti degli scarti di due variabili dalle rispettive medie
covarianza = σxy= codevianza divisa per N
devianza della distribuzione marginale di X = Dx = somma dei quadrati degli scarti dalla media per la sola X
varianza della distribuzione marginale di X = σxy= devianza divisa per N
ANALISI DEI RESIDUI DI UN MODELLO DI REGRESSIONE LINEARE


ESEMPIO DI ANALISI DEI RESIDUI DI UN MODELLO DI REGRESSIONE LINEARE
STUDIO DELL’ADATTAMENTO DELLA RETTA DI REGRESSIONE AI DATI: l’analisi di regressione non termina con la determinazione dei parametri del modello, ma include la verifica dell’idoneità del modello a rappresentare la relazione statistica tra le variabili X e Y, che avviene con la scomposizione della devianza totale in devianza spiegata (devianza di regressione) e devianza residua.
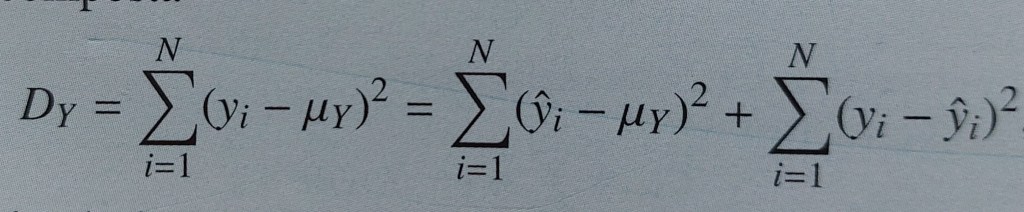

devianza della distribuzione marginale di Y = DY = somma dei quadrati degli scarti dalla media per la sola Y
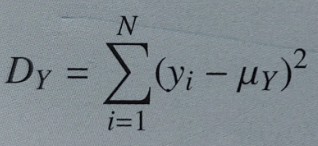
devianza spiegata = devianza di regressione = parte della variabilità totale dei valori di Y (variabilità totale misurata dalla devianza totale) attribuibile alla variabilità dei valori teorici forniti dalla retta di regressione , variabilità legata alla variabilità di X in virtù dell’equazione

devianza residua = devianza della distribuzione dei residui ei
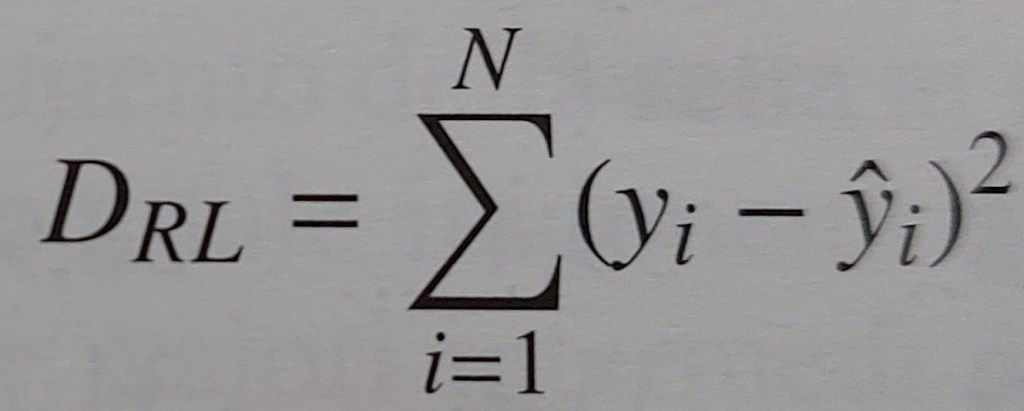
ESEMPIO DI SCOMPOSIZIONE DELLA DEVIANZA
indice di determinazione = rapporto tra devianza spiegata e devianza residua

PROPRIETÀ E CALCOLO DELL’INDICE DI DETERMINAZIONE
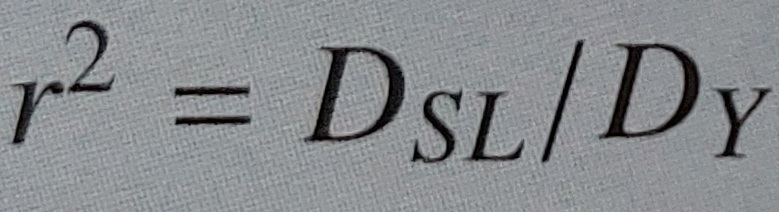
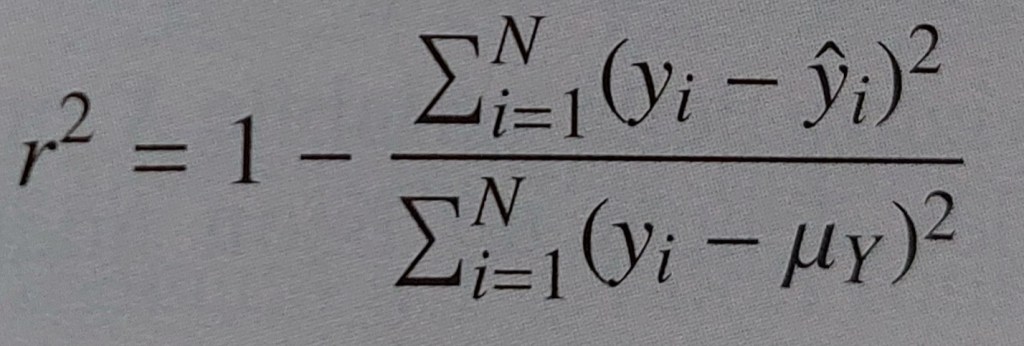

Poiché DSL=DY-DRL

IL CASO DELLE SERIE STORICHE
REGRESSIONE LINEARE NEL CASO DI DISTRIBUZIONI DOPPIE DI FREQUENZE (TABELLE A DOPPIA ENTRATA): DISAGGREGATE E DI FREQUENZA

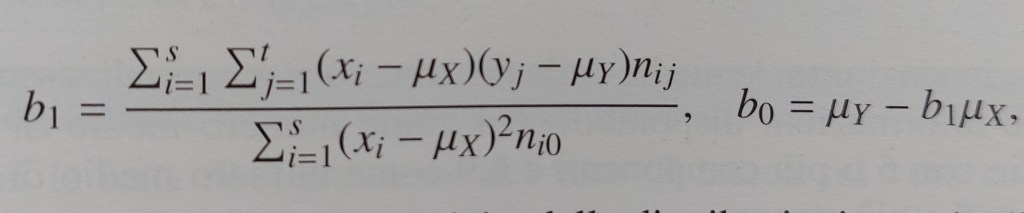
SCOMPOSIZIONE DELLA DEVIANZA TOTALE IN DEVIANZA SPIEGATA (DEVIANZA DI REGRESSIONE) E DEVIANZA RESIDUA NEL CASO DI DISTRIBUZIONI DOPPIE DI FREQUENZE
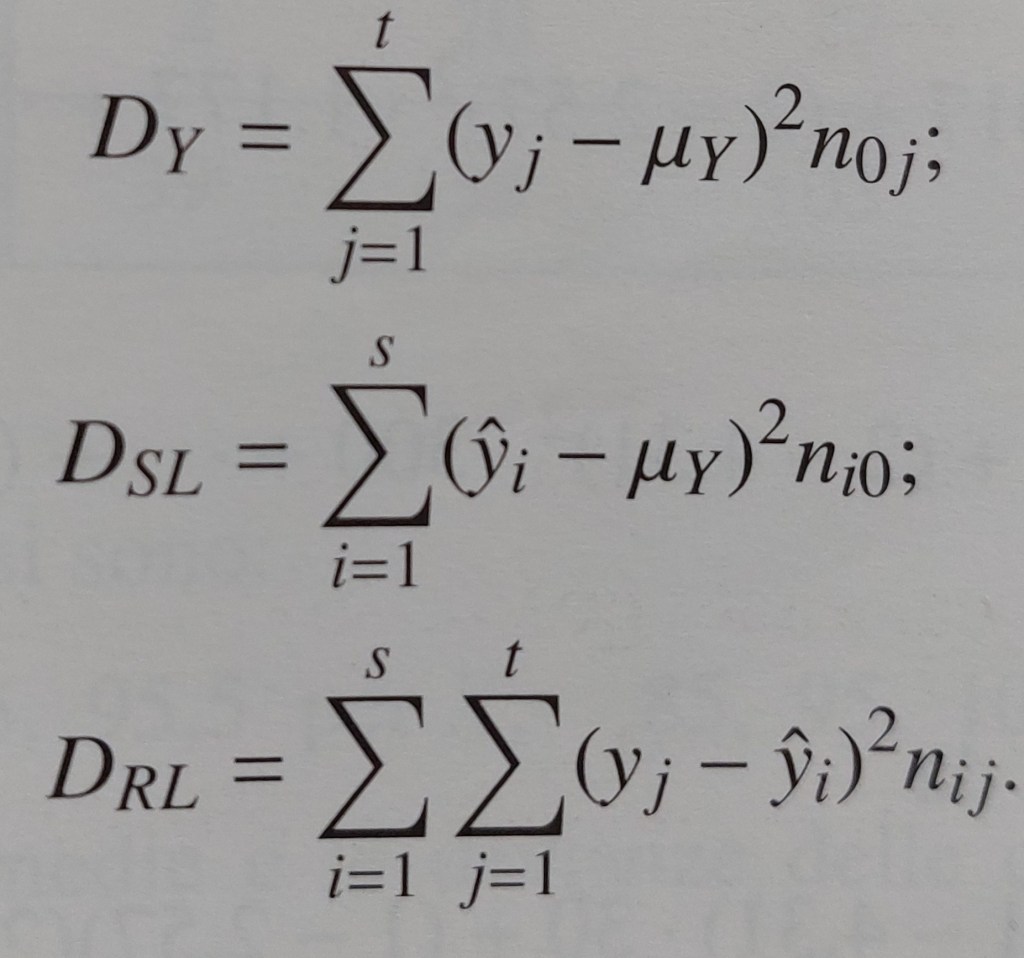
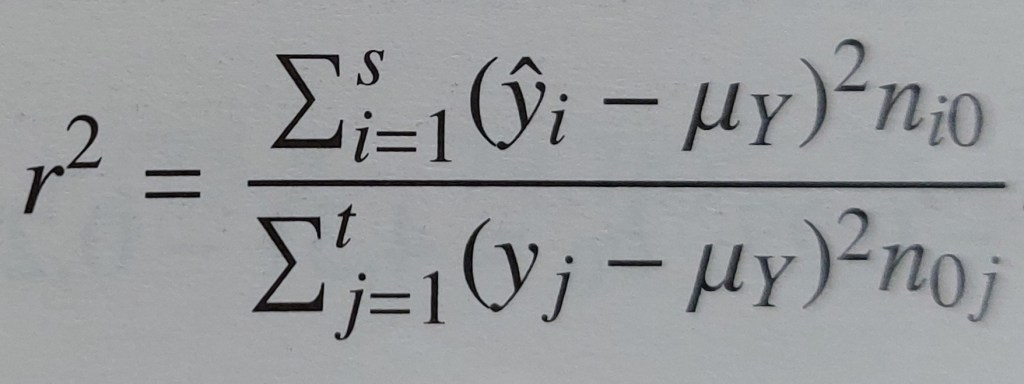
CORRELAZIONE (si calcola se non è ipotizzabile un rapporto di causa-effetto tra le variabili
ma queste dipendono, almeno in parte, da cause comuni)
(rapporto di) correlazione (tra due caratteri) = indice che misura la relazione esistente fra due caratteri quantitativi
scarto normalizzato corrispondente alla modalità (xi/yi)del carattere X/Y = misura della deviazione σx/σy dalla modalità dalla media rapportata alla distanza media delle modalità del carattere (xi/yi) dalla media μx/μy
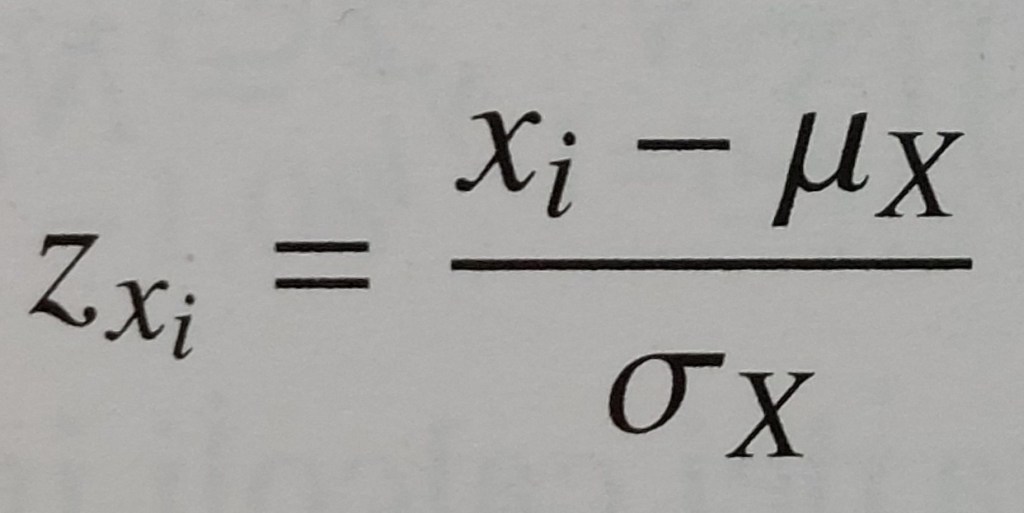
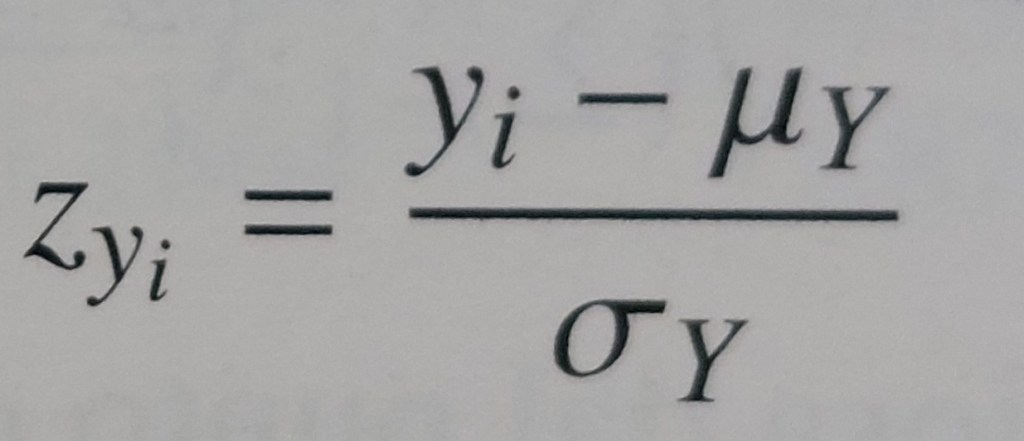
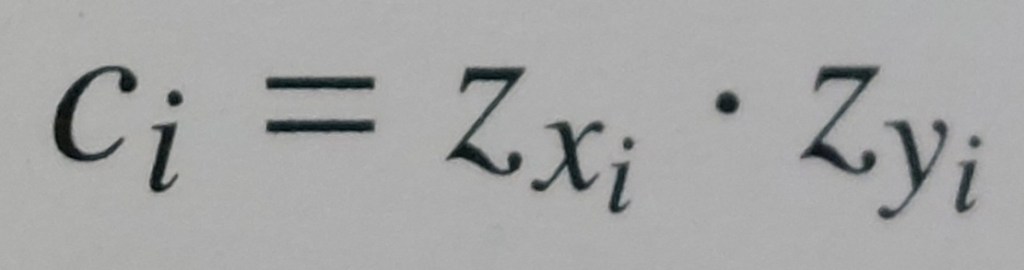
coefficiente di correlazione lineare di Bravais-Pearson = media aritmetica del prodotto i-esimo (ci) degli scarti standardizzati corrispondenti alle modalità i-esime di due caratteri (xi di X e yi di Y)
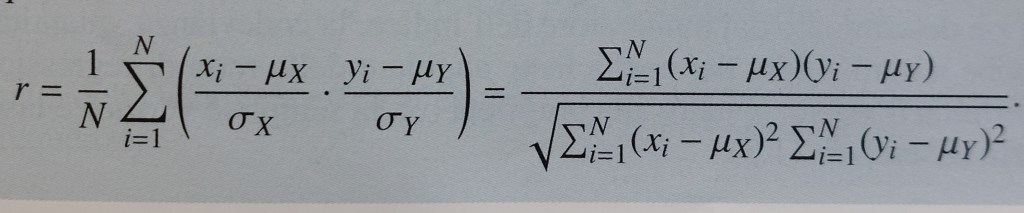
correlazione positiva = concordanza (tra due caratteri) = i caratteri tendono a crescere (o decrescere) insieme
correlazione negativa = discordanza = al crescere di un carattere l’altro tende a decrescere
INTERPRETAZIONE GEOMETRICA E PROPRIETÀ DEL COEFFICIENTE DI CORRELAZIONE LINEARE DI BRAVAIS
massima concordanza = corrisponde a un indice di correlazione pari a 1
massima discordanza = corrisponde a un indice di correlazione pari a -1
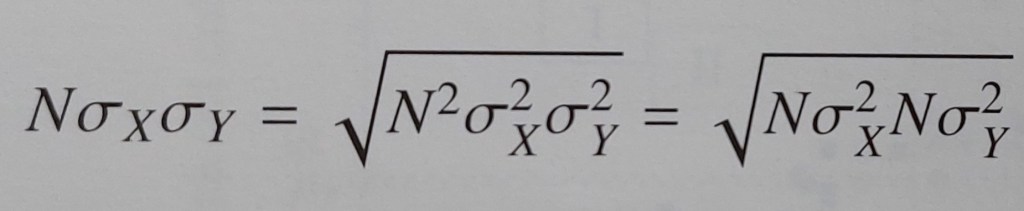


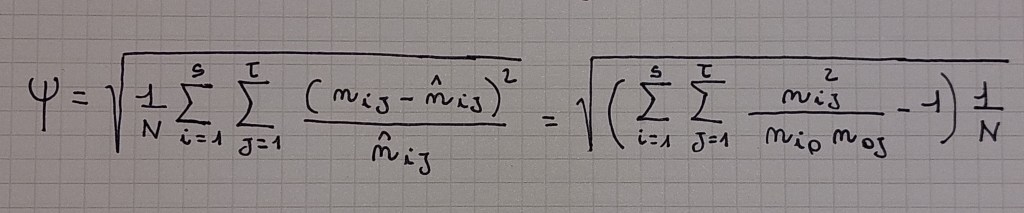
Il coefficiente di correlazione lineare di Bravais è caratterizzato dalle seguenti proprietà:


[…] rappresentazioni analitiche (indici) = indici di variabilità, indici di forma, numeri indici, analisi della dipendenza e dell’interdipendenza tra caratteri. […]
"Mi piace""Mi piace"