
INTRODUZIONE ALLA STATISTICA DESCRITTIVA UNIVARIATA
Riferimento al libro “Statistica: principi e metodi”: capitolo 1 “Nozioni introduttive”
La statistica descrittiva è la branca della statistica che studia i criteri di rilevazione, classificazione, sintesi e rappresentazione dei dati appresi dallo studio di una popolazione o di una parte di essa (detta campione).
La statistica descrittiva univariata prende in considerazione lo studio di una variabile alla volta come altezza, peso, età, rilevata sulle unità. Nello studio congiunto di due variabili si parla invece di analisi bivariata. Lo studio congiunto di due o più variabili è detto analisi multivariata (ovviamente il multivariato include il bivariato).
La statistica nelle scienze empiriche è nata come mezzo per stabilire se, in una determinata situazione, l’evidenza empirica (i dati osservati) sono in accordo con un’ipotesi o con una teoria scientifica.
Il ruolo della statistica è fondamentale nelle politiche basate sull’evidenza.
Esistono tuttavia delle problematiche di acquisizione dell’informazione.
Fasi dell’indagine statistica:
1. individuazione e descrizione dello scopo dell’attività
2. analisi della situazione di partenza
3. esame dei mezzi e degli strumenti da utilizzare
4. previsione dei risultati conseguibili
5. decisione finale
Terminologia essenziale:
(NOTA: in grassetto i termini specifici, in grassetto e sottolineati gli iperonimi, cioè i termini di significato più ampio, che comprende quello di uno o di più termini specifici, per alcuni dei quali si possono aprire degli approfondimenti cliccandovi sopra)
dati statistici = numeri in un contesto
collettivo statistico = molteplicità (insieme dei casi individuali) in cui si manifesta il fenomeno oggetto di studio. L’espressione collettivo statistico è appropriata sia per designare la totalità dei casi individuali in cui il fenomeno studiato si manifesta (popolazione) sia per indicare la “parte della totalità dei casi” che viene sottoposta a osservazione (campione)
popolazione = totalità dei casi in cui il fenomeno studiato si manifesta (totale dei soggetti di interesse in uno studio), che però, a differenza dell’universo, è delimitata nel tempo e nello spazio
campione = parte della totalità dei casi che viene sottoposta a osservazione (sottoinsieme della popolazione di riferimento dello studio) al fine di dare un’immagine ridotta ma fedele delle caratteristiche della popolazione
outlier = dato anomalo
unità statistica = caso individuale componente del collettivo statistico oggetto di studio. Equivale all’elemento su cui vengono osservati i caratteri oggetto di studio.
Esempi di unità statistiche sono le unità statistiche semplici, composte o multiple.
• unità statistiche semplici = autovetture, persone singole, lanci di monete;
• unità statistiche composte = aggregati di unità semplici, come le famiglie, le aziende;
• unità statistiche multiple = doppie, triple, … , formate da due, tre, … , unità semplici legate da un vincolo (come ad esempio, marito e moglie, soci di una società)
carattere = ogni aspetto elementare, ogni caratteristica oggetto di rilevazione nelle unità statistiche del collettivo; può essere definito anche come ogni possibile aspetto delle unità statistiche prese in considerazione (es: colore degli occhi)
modalità (del carattere) = i diversi modi con cui il carattere si manifesta sulle unità statistiche del collettivo; possono essere definite anche come le diverse manifestazioni (caratteristiche attraverso cui si manifesta il fenomeno osservato) del carattere assunte in corrispondenza di ogni individuo
Tipologie di caratteri:
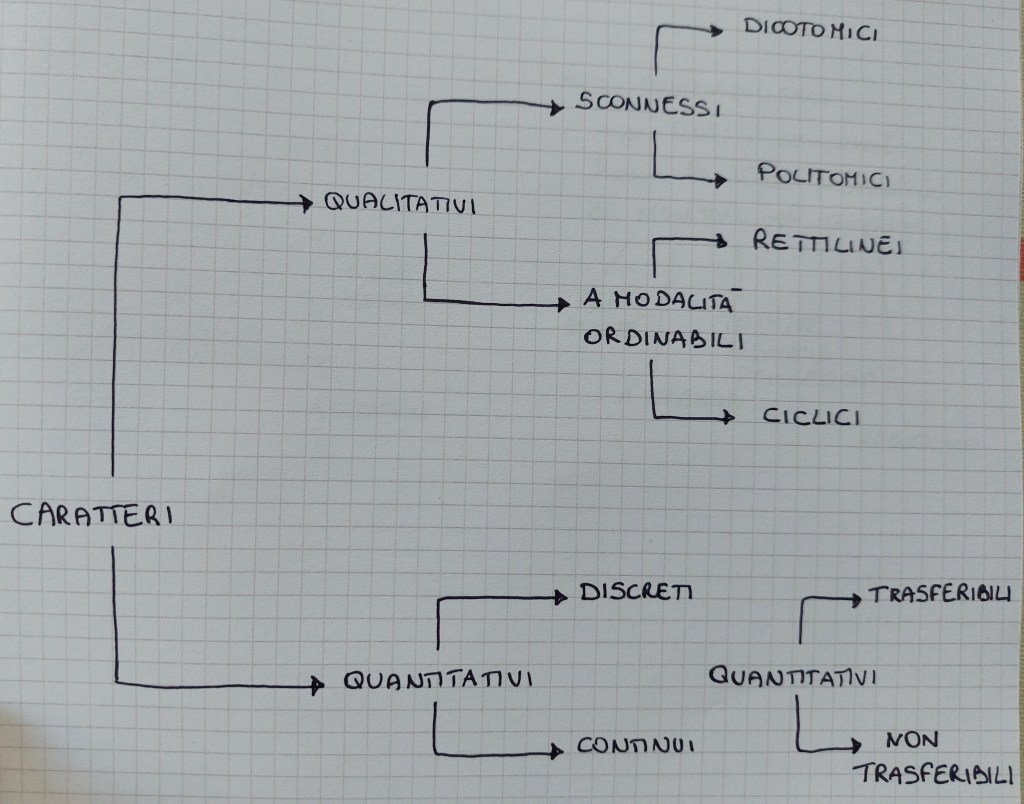
caratteri qualitativi (mutabili statistiche) = le modalità sono costituite da singole parole o da espressioni verbali (ad esempio aggettivi, avverbi, locuzioni). Si possono distinguere in sconnessi o ordinabili.
• caratteri qualitativi sconnessi = quelli in cui le modalità non presentano un ordine naturale di successione, cioè date due modalità distinte è possibile solo affermare se queste sono uguali o diverse (ad esempio il sesso, l’attività economica, la località di nascita). Tra di essi è possibile stabilire soltanto una scala nominale, che consente di classificare le unità del collettivo statistico in tanti gruppi omogenei distinti quante sono le modalità del carattere. Si possono distinguere in dicotomici o politomici.
• caratteri qualitativi sconnessi dicotomici = possono assumere due sole modalità, come nel caso del carattere sesso (maschio o femmina) o dell’esito di un esame universitario o di un concorso (superato o non superato)
• caratteri qualitativi sconnessi politomici = possono assumere un numero finito di modalità distinte, come ad esempio nel caso del colore di una stanza
• caratteri qualitativi a modalità ordinabili = le modalità presentano un ordine naturale, ossia se date due modalità è possibile dare loro un ordine, specificando che una precede l’altra, ad esempio il grado di soddisfazione per un servizio erogato dalla comunità (poco, abbastanza, molto), la posizione in una graduatoria o il titolo di studio (senza titolo, licenza elementare, licenza media, diploma, laurea triennale, laurea magistrale, dottorato). Si possono distinguere in rettilinei o ciclici
• caratteri qualitativi a modalità ordinabili rettilinei = se possiedono una modalità iniziale e una finale (es. il grado di soddisfazione o il grado di istruzione). Le modalità ammettono un ordine naturale di successione con una modalità iniziale ed una finale. Tra di essi è possibile stabilire soltanto una scala ordinale
scala ordinale = una scala che consente di classificare le unità del collettivo statistico in tanti gruppi omogenei e graduati in base all’ordine che le modalità presentano
• caratteri qualitativi a modalità ordinabili ciclici = caratteri che non hanno vere e proprie modalità iniziali e finali. Le modalità della distribuzione presentano un ordine naturale di successione, ma non si può dire, senza una convenzione, quale sia prima e quale sia l’ultima modalità (es. giorni della settimana o direzioni del vento)
caratteri quantitativi (variabili statistiche) = le modalità sono espresse da numeri (ad esempio età, peso, altezza, numero delle aziende)
• caratteri quantitativi continui = possono assumere tutti i valori di un certo intervallo di numeri reali. Sono tutte le osservazioni di un fenomeno collettivo che sono oggetto di un processo di misurazione (es. la statura degli individui)
• caratteri quantitativi discreti = le loro modalità sono quantità distinte, preventivamente individuabili ed elencabili, quasi sempre espresse da numeri interi. Sono tutte le osservazioni che sono oggetto di un processo di conteggio o enumerazione (es. numeri di vani delle abitazioni)
• caratteri quantitativi trasferibili = ha senso ipotizzare il trasferimento di parte del carattere da un’unità a un’altra (es. reddito o patrimonio delle persone)
• caratteri quantitativi non trasferibili = non ha senso ipotizzare il trasferimento di parte del carattere da un’unità a un’altra (es. altezza o peso delle persone)
caratteri di stato = fenomeni di stato = caratteri che variano nel tempo e per cui il tempo è un elemento di disturbo, per cui andrebbero misurati simultaneamente
caratteri di movimento = fenomeni di movimento = caratteri per cui il decorso del tempo è un elemento indispensabile per la rilevazione del carattere
classi = intervalli tra loro disgiunti in cui si suddivide l’insieme dei possibili valori
rilevazione totale = vengono rilevate tutte le unità di un collettivo o popolazione
rilevazione parziale o campionaria = vengono rilevate solo alcune unità della popolazione
intervallo di tolleranza = intervallo di valori possibili sotteso dalla misura annotata dal rilevatore, che presenta una deviazione rispetto alla misura effettiva non superiore alla metà dell’unità che esprime il livello di precisione prescelto (eccezione: misura del tempo)
scala per rapporti = il confronto può essere effettuato sia per differenza che per rapporto tra le modalità che le unità assumono. Il confronto per rapporto è possibile solo quando nella scala esiste uno zero assoluto che rappresenta l’assenza totale del fenomeno (es: scala delle altezze o dei pesi). Per maggiori dettagli clicca qui.
scala a intervalli = il confronto tra le modalità può essere effettuato solo per differenza, in quanto non esiste uno zero assoluto (esempi di scale a intervalli sono le scale Celsius e Farenheit per la misurazione della temperatura, poiché uguali differenze su ciascuna di queste scale rappresentano uguali differenze in temperatura, mentre non è vero che ad esempio una temperatura di 40 gradi sia il doppio di 20 gradi)
GENESI DEI DATI STATISTICI:
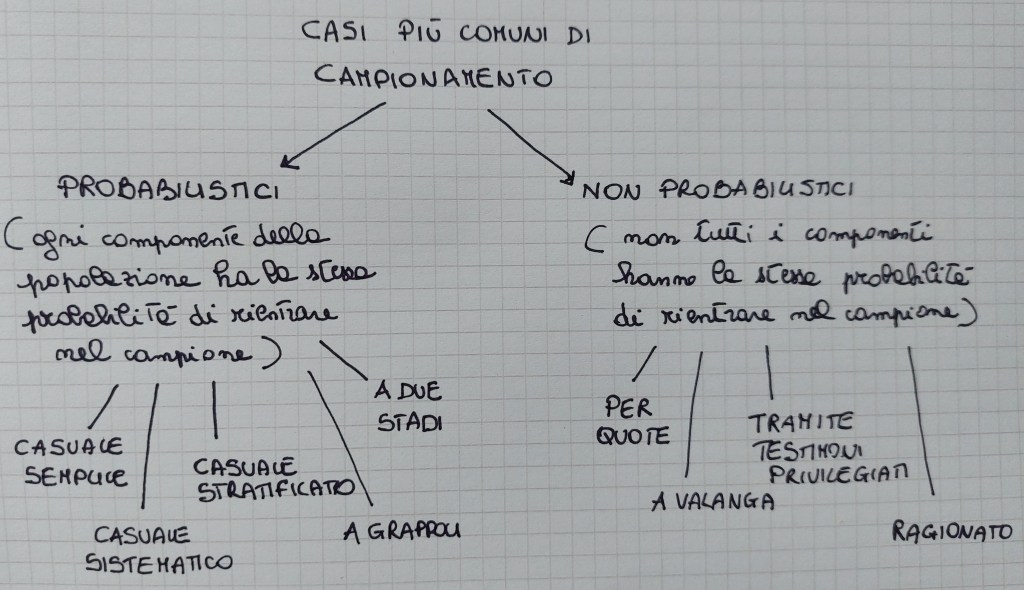
campionamento probabilistico = il campione è formato con meccanismo aleatorio, quindi siamo in grado di calcolare l’errore di campionamento, in quanto tutte le unità che compongono la popolazione hanno la stessa probabilità di far parte del campione. Questo tipo di campionamento risponde quindi alle leggi di probabilità. Può essere casuale semplice, stratificato, a grappolo, o di altri tipi misti tra questi.
- campionamento casuale semplice = tecnica che attribuisce la stessa probabilità di selezione a ogni insieme n unità distinte della popolazione. La probabilità che ogni unità della popolazione ha di essere scelta alla prima estrazione è 1/N. La selezione del campione può essere poi fatta in due modi: con reintroduzione (ciascun elemento della popolazione è disponibile a ogni estrazione e a ogni estrazione ogni unità ha sempre la probabilità 1/N di essere estratta) e senza reintroduzione (un’unità, una volta estratta, non viene rimessa nella popolazione).
- campionamento casuale sistematico = tecnica che attribuisce la stessa probabilità di selezione a ogni insieme n unità distinte della popolazione, che consta di N individui. Si definisce il passo di campionamento p (p=N/n se N è multiplo di n – ad esempio N=100 e n=25, il passo è 4 – o l’intero più vicino a N/n se N non è multiplo di n ad esempio N=93 e n=15, il passo è 6) e si seleziona casualmente un primo numero r minore o uguale a p, poi si prendono tutte le unità che hanno numero r, r+p, r+2p, ecc., fino ad arrivare a N, se è un multiplo di n, oppure a p*n? in caso contrario. Per usare questo metodo è necessario possedere una lista di campionamento.
- campionamento sistematico = si estrae a sorte soltanto la prima unità da intervistare e poi, dopo aver fissato la numerosità campionaria N, si intervista un individuo ogni intervallo k (k=N/n) che prende il nome di passo di estrazione. In questo caso la popolazione deve essere finita e quindi si deve disporre di una lista di campionamento
- campionamento stratificato (con variabile ausiliaria) = la popolazione viene suddivisa in sottopopolazioni dette “strati”, sulla base di alcune variabili chiave (che sappiamo essere correlate con la variabile oggetto dell’indagine) per lo studio del fenomeno collettivo oggetto di osservazione. Il campione si forma estraendo a caso un certo numero di unità da ogni strato, che è al suo interno omogeneo. Un campione stratificato prende in considerazione per l’analisi ogni strato (gli strati sono i differenti gruppi che vogliamo confrontare rispetto ad alcune loro caratteristiche, ad esempio uomini e donne). Nel primo stadio occorre stabilire la numerosità del campione per ogni strato con un criterio, scegliendo ad esempio la proporzione sull’intera popolazione dello strato stesso o calcolando la frazione di campionamento n/N costante per ogni strato, in modo che ciascuno di essi abbia lo stesso peso nel campione. In questo modo sono garantite contemporaneamente casualità e proporzionalità.
allocazione proporzionale del campione negli strati = selezione di un’uguale porzione da ciascuno strato
allocazione ottima(le) del campione negli strati = la numerosità assegnata ad uno strato è funzione, oltre che del numero di unità appartenenti allo strato, anche della variabilità interna allo strato e del costo della rilevazione delle unità dello strato
- campionamento a grappoli = utile quando non si dispone di liste complete delle popolazioni di interesse. Per la selezione del campione la popolazione deve essere suddivisa in un gran numero di grappoli come, ad esempio, i diversi isolati di una città. Si seleziona poi un campione casuale di questi grappoli e si impiegano nello studio tutti i soggetti contenuti nel grappolo Il campione a grappoli prende quindi in considerazione un campione di grappoli piuttosto che la loro totalità (i grappoli sono solo il mezzo che permette di identificare più agevolmente gruppi di soggetti).
- campionamento casuale a stadi = combinazione degli altri metodi: prima viene effettuato un campionamento a grappolo, poi, all’interno dei singoli grappoli individuati, non si prendono tutte le unità, bensì viene fatto un ulteriore campionamento casuale estratto dalle unità del grappolo
- campionamento a grappoli stratificato = ad esempio, si estrae casualmente, in ogni istituto scolastico, una sezione per ogni classe (prime, seconde, ecc.), in modo che le classi selezionate abbiano una cospicua probabilità di appartenere a sezioni differenti; e, in seguito, si sottopone il questionario a tutti gli studenti presenti in detta classe
Nella seguente immagine, tratta dal libro “Statistica, principi e metodi” di Chicchitelli, D’Urso e Minozzo, sono rappresentati alcuni tipi di campionamento.
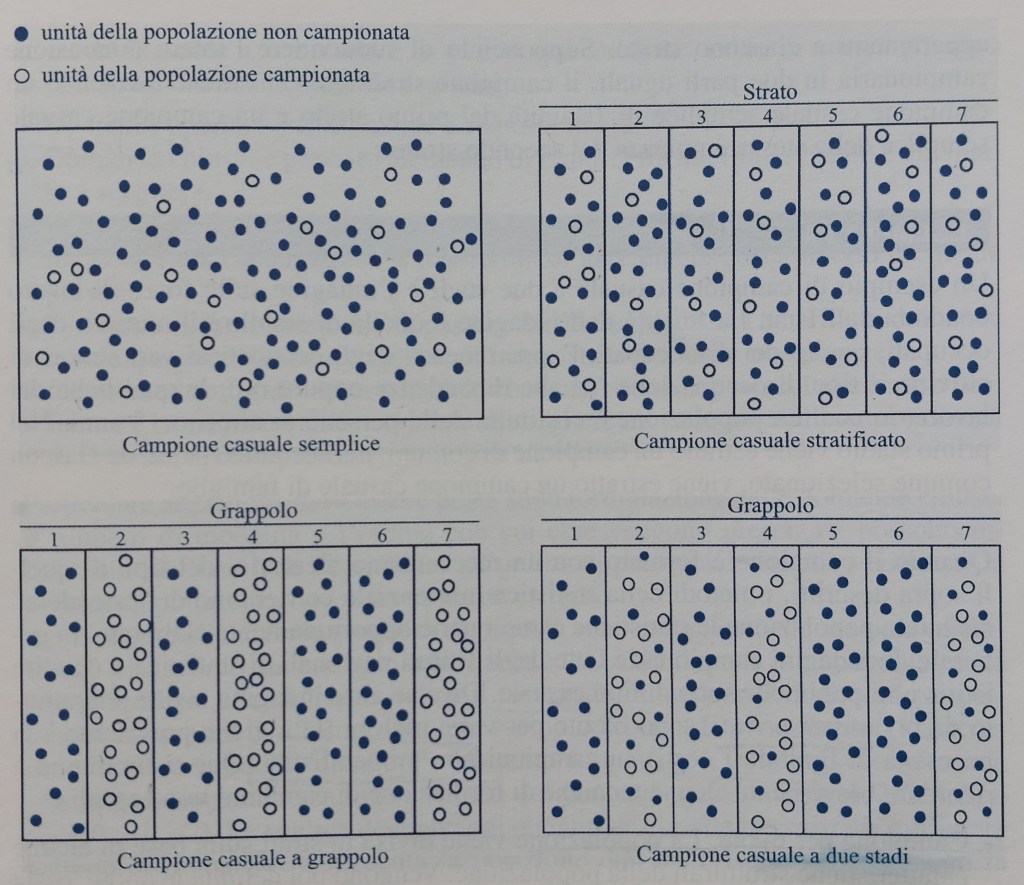
- campionamento a due stadi stratificato = ad esempio, se le unità di primo stadio sono le scuole, campionate con probabilità proporzionale alle dimensioni sulla base di una lista fornita dalle autorità di tutte le scuole eleggibili e le unità di secondo livello sono gli studenti. In ciascun paese è stato estratto un campione di almeno 150 scuole, all’interno di ciascuna delle quali si è estratto un campione di 35 quindicenni (prendendo tutti i quindicenni presenti qualora il loro numero fosse inferiore a 35) per un totale di almeno 4,500 studenti.
campionamento non probabilistico = il campionamento non è effettuato con meccanismo aleatorio, pertanto non rispondono a una legge di probabilità definita (non siamo in grado di calcolare l’errore di campionamento, in quanto non tutte le unità che compongono la popolazione hanno la stessa probabilità di far parte del campione) a priori e la selezione delle unità avviene secondo particolari esigenze conoscitive, in particolare a opera di organismi privati, che a differenza delle istituzioni pubbliche hanno la necessità di limitare i costi. I campioni non probabilistici sono:
• campionamento accidentale = il ricercatore utilizza i soggetti più vicini e disponibili per partecipare allo studio di ricerca
• campionamento per quote = molto simile al campionamento stratificato proporzionale in quanto il campione riflette la proporzione della popolazione complessiva. La principale differenza è che la scelta delle persone da intervistare non è fatta in modo casuale ma si lasci agli intervistatori la libertà di scelta delle persone di intervistare in funzione delle quote stabilite
• campionamento a valanga = si individua un primo gruppo di persone da intervistare e queste a loro volta ne individuano altre
• campionamento tramite testimoni privilegiati = si individuano le persone che, per gli studi svolti o per la professione esercitata, sono molto esperte sul fenomeno oggetto di studio
• campionamento ragionato (a scelta ragionata) = seguono una logica completamente opposta a quella dei campionamenti probabilistici, perché non vogliono casualità nella scelta
differenze = se a e b sono i livelli di uno stesso fenomeno espressi come grandezze omogenee, cioè nella stessa unità di misura, ma riferiti a situazioni o a unità diverse, il confronto tra le due quantità a e b può essere fatto tramite diverse differenze, dette assolute, relative e percentuali:
• differenze assolute = il confronto tra le quantità omogenee a e b viene effettuato tramite la differenza assoluta tra i due valori: b-a. (es. Giovanni è alto 1,84 metri, Alessandro 1,79 metri la differenza assoluta fra le loro masse è di 0,05 metri)
• differenze relative = se a e b sono i livelli di uno stesso fenomeno omogenei, cioè, espressi nella stessa unità di misura, ma riferiti a situazioni o a unità diverse, il confronto tra le quantità a e b viene effettuato dividendo b-a per a o per b. (es. Giovanni è alto 1,84 metri, Alessandro 1,79 metri la differenza assoluta fra le loro masse è di 0,05 metri e quella relativa è 0,05/1,84 o 0,05/1,79)
• differenze relative percentuali = il confronto tra le quantità omogenee a e b viene effettuato dividendo b-a per a o per b (ottenendo quindi la differenza relativa) e moltiplicando poi la differenza relativa per 100 (es. Giovanni è alto 1,84 metri, Alessandro 1,79 metri la differenza assoluta fra le loro masse è di 0,05 metri e quella relativa è (0,05/1,84)*100 o (0,05/1,79)*100)
• rapporti statistici = se a e b sono i livelli di uno stesso fenomeno espressi come grandezze omogenee, cioè nella stessa unità di misura, ma riferiti a situazioni o a unità diverse, il confronto tra le due quantità a e b può essere fatto tramite diversi rapporti: a/b (se esprimo il rapporto in termini di b) e b/a (se esprimo il rapporto in termini di a) oppure quelli detti di composizione, di coesistenza o di derivazione:
• rapporti di composizione = dato un insieme di grandezze omogenee (cioè espresse nella stessa unità di misura), a1, a2, …, ak, si effettuano i confronti delle singole grandezze con il totale A=a1+a2+…ak. I vari rapporti di composizione sono rappresentati da (ak/A)*100, con k numero naturale, e la loro somma è pari 100
• rapporti di coesistenza = dato un insieme di grandezze omogenee (cioè espresse nella stessa unità di misura), a1, a2, …, ak, si effettuano i confronti delle singole grandezze tra di loro. I rapporti di coesistenza hanno larga applicazione nell’analisi dei fenomeni demografici, ad esempio nel rapporto tra la popolazione di sesso maschile e quella di sesso femminile (rapporto di mascolinità) o nel rapporto tra i residenti con età di 65 anni e più e i residenti con meno di 15 anni (indice di vecchiaia)
• rapporti di derivazione = si istituiscono tra le misure di fenomeni connessi da specifici vincoli di associazione, ad esempio il rapporto, moltiplicato per mille, tra i nati in un anno e la popolazione residente media dell’anno (tasso di natalità)
metadati = informazioni sul processo di produzione dei dati, ossia sul dove, quando, come e da chi sono stati ottenuti
microdati = dati elementari che si riferiscono alle singole unità di rilevazione (es: dati relativi a ciascun intervistato)
macrodati = dati risultanti da calcoli effettuati sui microdati (es: dati aggregati per sesso degli intervistati).
metodi per l’analisi statistica dei dati = possono essere descrittivi o inferenziali
• statistica descrittiva riguarda la programmazione delle indagini censuarie, la rilevazione dei dati, la costruzione delle distribuzioni di frequenze o di quantità e la loro presentazione in forma grafica o tabellare, le elaborazioni statistiche mirate alla sintesi dei dati (come il calcolo dei rapporti statistici, il calcolo di medie, di variabilità e di forma) ed è uno strumento propedeutico per la formulazione di un’ipotesi o per la selezione del modello matematico adatto a descrivere il fenomeno.
• inferenza statistica (inversa) = l’insieme dei metodi che permettono di generalizzare i risultati basati su un’osservazione parziale del fenomeno d’interesse (come le indagini campionarie). L’inferenza statistica si avvale di due metodologie fondamentali: la verifica delle ipotesi e la stima dei parametri (intesi come grandezze riassuntive della popolazione oggetto di indagine), entrambe basate sul calcolo della probabilità.
DISTRIBUZIONI STATISTICHE
Riferimento al libro “Statistica: principi e metodi”: capitolo 2 “Distribuzioni statistiche”
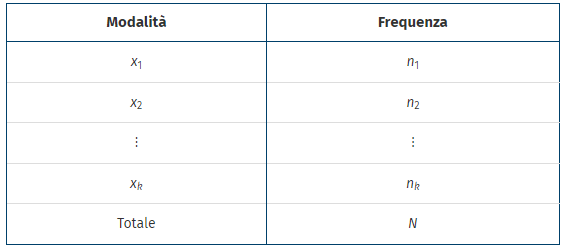
frequenza = frequenza assoluta = ni =numero delle volte in cui una modalità si presenta all’interno della variabile statistica
Considerando un collettivo statistico di N unità, dove sia osservato un carattere X, possiamo definire:
distribuzioni disaggregate = l’insieme delle osservazioni xi relative alle N unità del collettivo. In genere i valori relativi ai dati disaggregati vengono calcolati con semplici sommatorie.

distribuzioni di frequenze (assolute) = schema con cui si associa a ciascuna modalità del carattere X la rispettiva frequenza = classificazione e aggregazione di una distribuzione disaggregata in gruppi omogenei in modo disgiunto (la singola unità è assegnata a una e una sola modalità) ed esaustivo (esiste una modalità per ciascuna unità).
In genere i valori relativi ai dati distribuiti in frequenze assolute vengono calcolati con sommatorie in cui ogni termine viene moltiplicato per la frequenza assoluta e diviso per la popolazione totale N

• frequenze relative = fi = si ottengono rapportando le frequenze assolute ni al totale delle unità N.


In genere i valori relativi ai dati distribuiti in frequenze relative vengono calcolati con sommatorie in cui ogni termine viene moltiplicato per la frequenza relativa

• frequenze percentuali = pi = si ottengono moltiplicando le frequenze relative per 100
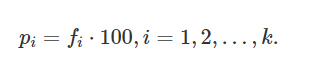

• frequenze (assolute) cumulate = Ni = si ottengono sommando la frequenza assoluta della modalità i presa in considerazione alle frequenze delle modalità precedenti
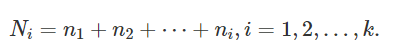

frequenze (relative) cumulate = Fi = si ottengono sommando la frequenza della modalità presa in considerazione alle frequenze delle modalità precedenti = f1 + f2 + … + fi

classi = intervalli numerici (tra loro disgiunti) comprendenti più modalità. Le k classi in cui è suddiviso il carattere X sono denominate: c0 – c1, c1 – c2, … , ck-1 – ck (dove il simbolo “-” , preceduto e seguito da spazi, non indica il segno meno, bensì significa “da…a”)

IPOTESI SU COME SONO DISTRIBUITE LE OSSERVAZIONI ALL’INTERNO DELLE CLASSI:
- tutte le unità della singola classe presentano la stessa modalità data dal valore centrale della classe
- uniforme distribuzione delle unità nelle classi: considerata la generica classe ci–1 – ci, di numerosità ni e di ampiezza di = ci-ci-1, la dividiamo in tanti intervallini quante sono le ni, ognuno di ampiezza di/ni e supponiamo che il singolo intervallino sia occupato da una sola unità, ove la modalità del carattere sia pari al valore centrale dell’intervallino. Di conseguenza, se consideriamo un intervallo di ampiezza pari a δ all’interno della classe, il numero di unità appartenenti a tale intervallo è pari a n(δ,i) = (ni/di)*δ = hi *δ
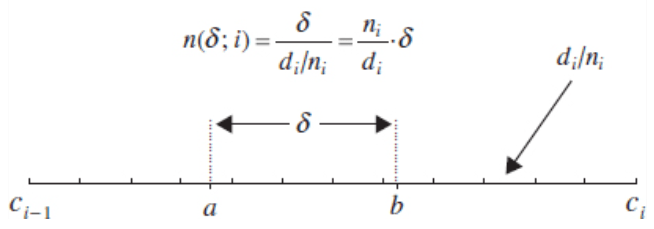
• classi reali = poiché a ogni osservazione di un carattere continuo corrisponde un intervallo di tolleranza, le classi reali si ottengono sottraendo all’intervallo sinistro e aggiungendo all’intervallo destro la stessa quantità, pari a metà dell’intervallo di tolleranza (ad esempio, se le osservazioni sono espresse da numeri interi, si sottrae 0,5 all’intervallo sinistro e si aggiunge 0,5 all’intervallo destro)
• chiusura (o meno) delle classi = l’inclusione (o meno) degli estremi della classe nella classe. Non ha senso se gli estremi di classe presentano una cifra decimale in più rispetto alle osservazioni (nel caso di limiti reali) o se la precisione delle osservazioni è maggiore di quella dei limiti di classe
• distribuzione di frequenze con modalità raggruppate in classi = schema che associa a ciascuna classe in cui è suddiviso il carattere X la rispettiva frequenza (assoluta o relativa)
• ampiezza di una classe = di = differenza tra estremo destro e estremo sinistro della classe = ci-ci-1
• valore centrale di una classe = x̄i = media tra gli estremi di una classe = (ci+ci-1)/2
• densità di frequenza = hi = ni/di = rapporto tra frequenza della classe ni e ampiezza della classe di
• frequenze cumulate (per classi) = si ottengono sommando la frequenza della classe presa in considerazione alle frequenze delle classi precedenti
In genere i valori relativi ai dati distribuiti in classi vengono calcolati con sommatorie in cui ogni termine viene moltiplicato per la numerosità della classe diviso il numero totale delle unità

distribuzione semplice = riguarda un solo carattere (c’è una singola colonna nella matrice dei dati)
distribuzioni doppie = si esaminano congiuntamente due caratteri nelle unità statistiche del collettivo
distribuzioni multiple = si esaminano congiuntamente più di due caratteri nelle unità statistiche del collettivo
distribuzione di quantità = lo schema con cui si associa a ogni modalità del carattere X il totale dello stesso o di un altro carattere posseduto dalle unità che presentano quella data modalità di X (attenzione: non contiamo le unità statistiche come nel caso delle distribuzioni di frequenze, ma sommiamo quantità trasferibili, come ad esempio considerando i consumi di energia elettrica in GWH per diverse categorie di utilizzatori)
serie storica = i dati statistici di interesse vengono associati a modalità temporali (istanti o intervalli di tempo successivi). A seconda della natura del fenomeno, la serie storica si configura come distribuzione di frequenze o distribuzione di quantità
serie territoriale = i dati statistici di interesse vengono associati a modalità territoriali (regioni, province, comuni, …). A seconda della natura del fenomeno, la serie territoriale si configura come distribuzione di frequenze o distribuzione di quantità
fenomeni di stato = i caratteri cambiano con il tempo, quindi bisognerebbe misurarli simultaneamente, in quanto il tempo è un fattore di disturbo RIPETUTO?
fenomeni di flusso = i caratteri sono soggetti a rinnovamento continuo e la loro rilevazione va effettuata in intervalli di tempo (es. nascite), in quanto il tempo è un elemento indispensabile per la rilevazione del carattere
RAPPRESENTAZIONI GRAFICHE
Riferimento al libro “Statistica: principi e metodi”: capitolo 3 “Rappresentazioni grafiche”
diagramma ad aste = riporta sull’asse delle ascisse le modalità x1, x2, …, xk e sull’asse delle ordinate le frequenze assolute corrispondenti n1, n2, …, nk oppure sull’asse delle ascisse le modalità x1, x2, …, xk e sull’asse delle ordinate le frequenze relative corrispondenti n1, n2, …, nk
funzione di ripartizione per caratteri quantitativi discreti = riporta sull’asse delle ascisse le modalità x1, x2, …, xk e sull’asse delle ordinate le frequenze cumulate corrispondenti F1, F2, …, Fk (le frequenze relative delle unità del collettivo per cui X ≤ x)
PROPRIETÀ DELLA FUNZIONE DI RIPARTIZIONE PER CARATTERI QUANTITATIVI DISCRETI:
F (x) = 0 per x < x1 (perché nel collettivo statistico non ci sono unità con modalità più piccole di xi)
F (x) = Fi per xi ≤ x < xi+1 (funzione costante a tratti che presenta dei salti in corrispondenza delle modalità x1, x2, …, xk
F (x) = 1 per x ≥ xk (perché nel collettivo statistico tutte le unità hanno modalità più piccole di xk)
rappresentazioni grafiche per caratteri quantitativi continui divisi in intervalli
istogramma di frequenze = riporta sull’asse delle ascisse gli estremi di classe c0, c1, …, ck e per ogni classe ci-1 – ci un rettangolo avente per base il segmento dell’asse delle ascisse di estremi ci-1 e ci e per altezza la densità di frequenza hi = ni/di AREA NI???
funzione di ripartizione per caratteri quantitativi continui = riporta sull’asse delle ascisse gli estremi di classe c0, c1, …, ck e sull’asse delle ordinate, in corrispondenza dell’estremo destro di ogni classe, le frequenze cumulate corrispondenti alle classi c1,…,ck: F1=F(c1), F2=F(c2),…, Fk=1 (le frequenze relative delle unità del collettivo per cui X ≤ x)
PROPRIETÀ DELLA FUNZIONE DI RIPARTIZIONE PER CARATTERI QUANTITATIVI CONTINUI:
F (x) = 0 per x ≤ c0 (perché nel collettivo statistico non ci sono unità con modalità più piccole di c0)
F (x) = Fi-1 + (ni/di)(x–ci-1)/N per ci-1 ≤ x < ci , con i=1,2,…,k (funzione costante a tratti che presenta dei salti in corrispondenza delle modalità c0, c1, …, ck-1) dove (ni/di)(x–ci-1) è il numero di unità comprese tra ci-1 e x
F (x) = 1 per x ≥ ck (perché nel collettivo statistico tutte le unità hanno modalità più piccole di ck)
rappresentazioni grafiche per serie sconnesse = di solito sono grafici di tipo areale, in cui alle modalità del carattere si fanno corrispondere figure geometriche con aree proporzionali alle grandezze da rappresentare (che siano frequenze o quantità)
• grafico a nastri (aste o barre) = i grafici di tipo areale sono rappresentati mediante settori circolari
• settori circolari (diagrammi a torta) = i grafici di tipo areale sono rappresentati mediante rettangoli
rappresentazioni grafiche per serie storiche: diagrammi cartesiani con i tempi sull’asse delle ascisse e le intensità associate sull’asse delle ordinate
rappresentazioni grafiche per serie territoriali: la più tipica è il cartogramma, in cui le ripartizioni territoriali sono individuate sull’appropriata cartina geografica, in cui le intensità corrispondenti (frequenze o quantità) vengono rappresentate tramite colori o tratteggi diversi, con l’ausilio di una legenda
MEDIE
Riferimento al libro “Statistica: principi e metodi”: capitolo 4 “Medie”
medie = si distinguono in due tipologie: medie analitiche (o ferme), o medie di posizione (o lasche)
(proprietà di) invarianza: se sostituisco la media ai termini della distribuzione la media non cambia
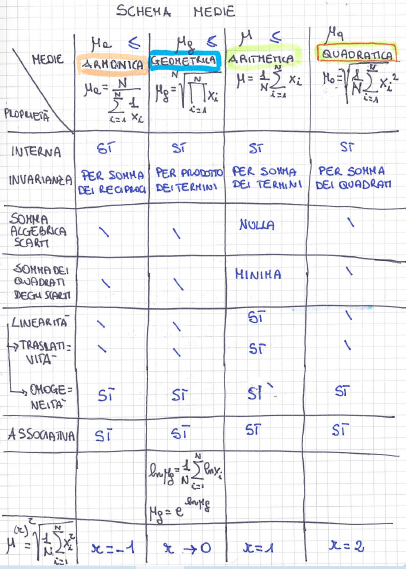
medie analitiche (o ferme) (proprietà ed esempi di applicazione) = si ottengono dall’applicazione di opportune operazioni matematiche a tutti i valori del carattere che formano la distribuzione statistica considerata. Tra queste vi sono la media aritmetica, la media geometrica, la media quadratica.
• media aritmetica (di n numeri) = il numero che si ottiene dividendo la loro somma per n (di conseguenza moltiplicando la media per N si ottiene il totale del carattere della distribuzione)



• media armonica

• media geometrica

• media quadratica

• medie di potenza

• medie analitiche per le distribuzioni di frequenze e loro calcolo
• media aritmetica per una distribuzione di frequenze a modalità raggruppate in classi = rapporto tra la somma algebrica dei prodotti di ciascuna frequenza per la propria modalità, e la somma delle frequenze
• media aritmetica ponderata = rapporto tra la somma dei prodotti di ciascun numero per il rispettivo peso e la somma dei pesi
• media armonica ponderata = rapporto tra la somma dei prodotti di ciascun termine della media armonica per il rispettivo peso e la somma dei pesi
• media geometrica ponderata = prodotto dei valori ponderati (elevando a potenza per un peso intero ciascun elemento) messo sotto radice con indice di radice pari alla somma dei pesi ciascun elemento
• media quadratica ponderata = rapporto tra la somma dei prodotti di ciascun termine della media quadratica per il rispettivo peso e la somma dei pesi
medie di posizione (o lasche) = medie la cui determinazione coinvolge solo alcuni valori della distribuzione. Tra queste ci sono la mediana e la moda.
mediana = indice di tendenza centrale che si applica ai caratteri qualitativi e quantitativi ordinabili e divide un insieme ordinato in due parti uguali, in modo tale che metà di essi sia più piccola e metà di essi più grande della mediana stessa
mediana per una distribuzione disaggregata = valore intermedio fra gli estremi di una successione finita e ordinata di valori
proprietà della mediana = la mediana presenta le proprietà di essere interna, lineare (di godere quindi della traslatività e della omogeneità) e di essere il valore che minimizza la somma dei valori assoluti degli scarti

mediana per una distribuzione di frequenze = si calcola determinando tutte le frequenze cumulate e individuando le frequenze cumulate consecutive tali che il totale diviso 2 si trovi compreso tra esse, poi si usano le modalità corrispondenti a queste frequenze
mediana per una distribuzione di frequenza per classi = si calcola individuando prima la classe mediana, poi calcolando il valore della mediana all’interno di essa
terzili = due indici di posizione di un carattere quantitativo oppure qualitativo ordinabile che dividono un insieme finito e ordinato di valori in tre parti uguali
quartili = tre indici di posizione di un carattere quantitativo oppure qualitativo ordinabile dividono un insieme finito e ordinato di valori in quattro parti uguali
decili = nove indici di posizione di un carattere quantitativo oppure qualitativo ordinabile dividono un insieme finito e ordinato di valori in dieci parti uguali
quantili = indici di posizione che lasciano al di sopra, o al di sotto, una determinata quantità di valori dati (ad esempio mediana, terzili, quartili e decili sono quantili)
moda per una distribuzione di frequenze = modalità caratterizzata dalla massima frequenza
moda per una distribuzione di frequenza per classi = la classe di modalità caratterizzata dalla massima frequenza
valore centrale = media aritmetica tra i valori estremi

[…] statistica descrittiva univariata = distribuzioni statistiche, rappresentazioni tabellari, rappresentazioni grafiche, rappresentazioni parametriche. […]
"Mi piace""Mi piace"